본 글은 이유한님의 Kaggle-KR 강의를 학습하여 작성하였습니다.
이유현님의 강의 링크
https://kaggle-kr.tistory.com/38
Porto Seguro’s Safe Driver Prediction[1] @홍정호, KQNG
--- competition: Porto Seguro’s Safe Driver Prediction original kernel: https://www.kaggle.com/bertcarremans/data-preparation-exploration share: @h0609zxc, 홍정호, KQNG date: 2019.07.12 --- 유한님이 만든 커리큘럼에 있는 커널 중 하나
kaggle-kr.tistory.com
Porto Seguro's Safe Driver Prediction 문제 링크
https://www.kaggle.com/competitions/porto-seguro-safe-driver-prediction
Porto Seguro’s Safe Driver Prediction | Kaggle
www.kaggle.com
목차
1. PorteSeguro 대회 문제 설명
2. Library & Dataset 소개
3. 탐색적 데이터 분석
1. PorteSeguro 대회 문제 설명
흔히 보험사에서는 고객 각각의 건강상태, 과거 병력, 연령대 등 다양한 배경을 고려하여 보험금의 가격을 책정합니다.
브라질에서 가장 큰 보험사 중 하나인 Porto Seguro는, 운전자의 다양한 조건을 고려하여 안전한 운전자에게는 적은 보험료를, 위험한 운전자에게는 높은 보험료를 책정하는 합리적인 시스템을 구축하고자 합니다.
우리는 주어진 운전자가 다음 해 얼마의 보험료를 지불해야하는지를 도출하는 모델을 빌드해야합니다.
2. Library & Dataset 소개
이번 데이터셋 분석에 사용할 라이브러리는
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import VarianceThreshold
from sklearn.feature_selection import SelectFromModel
from sklearn.utils import shuffle
from sklearn.ensemble import RandomForestClassifier
pd.set_option('display.max_columns',100)
pd.set_option('display.max_rows',100) #행과 열 보여주는 개수 최댓값 정해둠.
※ 2020년 이후로 sklearn.preprocessing 클래스에 있던 imputer이 sklearn.impute로 따로 파생되었습니다.
원본 커널과는 다른 부분이니 주의하시기 바랍니다!

이야기에 앞서 주어진 데이터를 펼쳐보도록 하겠습니다.
데이터를 훑어보면
1) 이진데이터가 존재함
2) 변수는 정수, 실수로 되어있음
3) 주어진 data column에서 -1로 주어진 데이터는 유실 데이터.
4) 타겟 변수와 ID변수가 존재함
이 네 가지 특징을 확인할 수 있습니다.
1주차에서 했던 타이타닉 예제는 이미 일어난 사건이기 때문에, 정적이고 확실한 데이터셋과 답안이 존재합니다.
하지만 이번주차부터는 확정적인 답안이 존재하지 않습니다. 데이터셋 역시 일부 '불순물'이 끼어있습니다.
따라서, 데이터를 분석하고 활용할 때, 필요한 데이터와 그렇지 않은 데이터를 골라내어야 합니다.
이번 주차는 이 점에 유의하시기 바랍니다.
3. 탐색적 분석
중복되는 값을 전부 솎아낸 후, 각 변수의 datatype이 어떤 형태인지 표로 정리합니다.
data = []
for f in train.columns:
if f=='target':
role = 'target'
elif f=='id':
role= 'id'
else:
role = 'input'
if 'bin' in f or f =='target':
level = 'binary'
elif 'cat' in f or f == 'id':
level = 'nominal'
elif train[f].dtype == float:
level = 'interval'
elif train[f].dtype == int:
level ='ordinal'
keep = True
if f=='id':
keep = False
dtype = train[f].dtype
f_dict = {
'varname':f,
'role': role,
'level': level,
'keep': keep,
'dtype': dtype
}
data.append(f_dict)
meta = pd.DataFrame(data, columns=['varname','role', 'level','keep','dtype'])
meta.set_index('varname',inplace=True)이를 'meta'명령어를 통해 펼치면 아래와 같은 결과값이 나옵니다.

다음은 Interval 변수를 활용해 각각 변수의 range를 파악해봅시다.
v = meta[(meta.level == "interval") & (meta.keep)].index
train[v].describe()
reg변수는 ps_reg03에만 누락값이 있고, 변수들마다 range가 제각각입니다. 스케일링을 할 수는 있겠으나. 우리가 사룡하려는 분류기마다 다르게 적용해야 할 것입니다.
car변수는 ps_car_12와 15에만 누락값이 있고, 변수들마다 범위가 다르지만 스케일링이 가능합니다.
calc변수는 누락값이 없습니다. 최대가 0.9인 어떤 비율일 것이며, 3개의 calc변수는 모두 유사한 분포를 갖고 있습니다.
이외에도 Ordial 변수, Binary 변수를 통해 각각 변수에 스케일링을 적용하고, 적용한 값의 데이터 선험을 확인할 수 있습니다.
그런데 앞에서, train.tail()의 결과를 보면 0의 비율이 1의 비율과 비교했을 때 압도적으로 높은 것을 확인 할 수 있습니다.
저번 시간에 이렇게 한 category data에 대한 분포가 쏠려있다면, 이 category가 과연 결과 예측에 정말 유용한 데이터인지 확인할 필요가 있다고 했습니다.
이번 시간에는 이를 실제로 확인해보는 작업을 해보겠습니다.
desired_apriori=0.10
idx_0 = train[train.target == 0].index
idx_1 = train[train.target == 1].index
nb_0 = len(train.loc[idx_0])
nb_1 = len(train.loc[idx_1])
undersampling_rate = ((1-desired_apriori)*nb_1)/(nb_0*desired_apriori)
undersampled_nb_0 = int(undersampling_rate*nb_0)
print('Rate to undersample records with target=0: {}'.format(undersampling_rate))
print('Number of records with target=0 after undersampling: {}'.format(undersampled_nb_0))
undersampled_idx = shuffle(idx_0, random_state=37, n_samples=undersampled_nb_0)
idx_list = list(undersampled_idx) + list(idx_1)
train = train.loc[idx_list].reset_index(drop=True)
print(train.shape)
train["target"].value_counts()

이제, 누락된 값을 검사하여 유효한 데이터와 그렇지 않은 데이터를 고르겠습니다.
vars_with_missing = []
for f in train.columns:
missings = train[train[f] == -1][f].count()
if missings > 0:
vars_with_missing.append(f)
missings_perc = missings / train.shape[0]
print('Variable {} has {} records ({:.2%}) with missing values'.format(f, missings, missings_perc))
print('In total, there are {} variables with missing values'.format(len(vars_with_missing)))
- ps_car_05_cat, ps_car_03_cat번은 누락된 값의 비율이 너무 높으므로 데이터셋에서 아예 제거합니다.
- ps_reg_03은 모든 레코드의 18%에 대해 값이 누락되었습니다. 기존 값을 지우고, 평균 값으로 바꿔줍시다.
- ps_car_11: 누락된 값이 있는 레코드는 5개뿐이므로 모드로 교체합니다.
- ps_car_12: 누락된 값이 있는 레코드는 1개뿐이므로 기존 값을 지우고, 평균 값으로 바꿔줍니다.
- ps_car_14: 모든 레코드의 7%에 대해 값이 누락되었습니다. 기존 값을 지우고 평균값으로 바꾸어줍니다.
이 부분까지 수행하였으면, 이번 주차에선 카디널리티를 활용해보겠습니다.
카디널리티는 변수에 존재하는 서로 다른 값들의 개수를 뜻합니다.
이번주차의 데이터같은, 범주형 변수의 경우, 데이터 처리를 위해 더미 변수를 넣어주는 경우가 있습닏.
때문에 서로 다른 값들의 변수가 있는 지를 확인해야합니다. 확인한 변수는 더미 변수와 다르게 처리해주어야 하기 때문입니다.
v = meta[(meta.level == 'nominal') & (meta.keep)].index
for f in v:
dist_values = train[f].value_counts().shape[0]
print('Variable {} has {} distinct values'.format(f, dist_values))
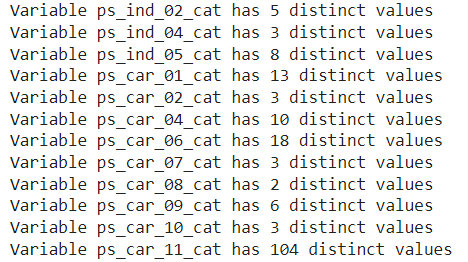
이제 본격적으로 범주형 변수를 다루어보겠습니다.
앞에서 범주형 변수별로 값의 범위를 어느정도 가늠해보았으니, 이제 이를 토대로 타겟변수가 1인 고객의 범주형 변수와 비율을 살펴보겠습니다.
v = meta[(meta.level == 'nominal') & (meta.keep)].index
for f in v:
plt.figure()
fig, ax = plt.subplots(figsize=(20,10))
cat_perc = train[[f, 'target']].groupby([f],as_index=False).mean()
cat_perc.sort_values(by='target', ascending=False, inplace=True)
sns.barplot(ax=ax, x=f, y='target', data=cat_perc, order=cat_perc[f])
plt.ylabel('% target', fontsize=18)
plt.xlabel(f, fontsize=18)
plt.tick_params(axis='both', which='major', labelsize=18)
plt.show();
먼저, 범주형 값 당 타겟값이 1인 변수들의 총 비율을 계산해줍니다. 이후 타겟을 평균으로 내림차순하여 출력해봅시다.


누락된 값이 있는 변수들의 그래프를 보면, 모드를 사용하는 것 대신, 누락된 값을 별도의 범주 값으로 유지하는 것이 데이터 처리에 더 효율적인 것으로 보입니다.
누락된 값을 나타내는 고객들은 보험금 청구를 요구할 확률이 훨씬 더 높기 때문입니다. (만약 누락된 값을 나타내는 고객들이 관계없는 데이터였다면 값을 유지할 필요도 없이 삭제하면 됩니다!)
다음으로 Interval 변수 간의 상관관계, ordinal 변수 간의 상관 관계를 확인합니다.
1주차에서, 두 변수 사이의 상관관계를 확인하기 위해 히트맵을 그렸었는데요,
이번에도 같은 방법으로 상관관계를 파악해보겠습니다.
def corr_heatmap(v):
correlations = train[v].corr()
cmap = sns.diverging_palette(220, 10, as_cmap=True) #색상은 임의로 변경 가능합니다.
fig, ax = plt.subplots(figsize=(10,10)) #사이즈 역시 임의로 조절해도 무관합니다!!
sns.heatmap(correlations, cmap=cmap, vmax=1.0, center=0, fmt='.2f', square=True, linewidths=.5, annot=True, cbar_kws={"shrink": .75})
plt.show();
v = meta[(meta.level == 'interval') & (meta.keep)].index
corr_heatmap(v)
분석해보면
- ps_reg_02, ps_reg_03
- ps_car_12, ps_car_13
- ps_car_12, ps_car_14
- ps_car_13, ps_car_15
이 변수들 간에는 강한 상관관계가 존재하는 것을 볼 수 있습니다.
(※ 1.00으로 표시된 대각선은 자기 자신과의 상관관계를 출력한 것입니다! 실제 분석과는 무관합니다.)
이후 각 변수들 간의 관계는 lmplot함수로 그래프를 그려 확인해봅니다.
ordinal 변수 간의 상관관계도 동일한 방법으로 파악해봅시다.
v = meta[(meta.level == 'ordinal') & (meta.keep)].index
corr_heatmap(v)
ordinal 변수 간에는 눈에 띄는 상관관계가 없습니다.
변수 간의 상관관계를 중심으로 피처 엔지니어링을 해주어야 합니다.
피처 엔지니어링이란, 모델을 트레이닝시키는 데에 사용되는 머신 러닝 알고리즘 성능 향상을 위해 데이터를 변환하고, 개선하는 프로세스 입니다.
이번 예제에서는 범주형 데이터들 중 더미 데이터를 갖고 있었던 변수들을 변환하고, 개선하면 되겠습니다.
이후 모델 성능 향상을 위해 이 데이터 중에서 분류 알고리즘이 유지할 피처를 골라내고, 골라낸 피처를 다시금 스케일링하여 데이터에 적용시키면 완성입니다!
범주형 변수는 순서 또는 크기를 나타내지 않습니다.
(카테고리 2는 카테고리 1의 값의 2배가 아닙니다. value가 아니라 그냥 기호 정도로 봐주시면 되겠습니다.)
그러므로, 카테고리 값을 다루기 위해 더미 변수를 만들어줍니다.
v = meta[(meta.level == 'nominal') & (meta.keep)].index
print('Before dummification we have {} variables in train'.format(train.shape[1]))
train = pd.get_dummies(train, columns=v, drop_first=True)
print('After dummification we have {} variables in train'.format(train.shape[1]))이 때, train.shape[1]에 저장된 더미 변수는 실제와는 다른, 유효하지 않은 data가 들어올 수 있으므로 삭제한 것입니다.
이제 interaction 변수를 만들어줍니다.
v = meta[(meta.level == 'interval') & (meta.keep)].index
poly = PolynomialFeatures(degree=2, interaction_only=False, include_bias=False)
interactions = pd.DataFrame(data=poly.fit_transform(train[v]), columns=poly.get_feature_names(v))
interactions.drop(v, axis=1, inplace=True)
train = pd.concat([train, interactions], axis=1)위와 같은 코드를 통해 train dataset에 새로운 interaction 변수를 추가해줍니다.
train.head()를 입력하면
아래와 같은 결과를 볼 수 있습니다.

마지막으로, 피처를 선택한 후 피처 스케일링을 해봅시다!
피처를 선택할 때, 차후 분류 알고리즘을 돌렸을 때 살아남을만한, 즉 결과 예측에 유효한 data만 골라내는 것이 효율적일 것입니다.
그러기 위해선 변화가 없거나 미미한 피처, 즉 분산이 낮거나 0인 피처를 제거해주면 됩니다!
분산이 0인 것은 앞에서 지워줬으니, 분산이 낮은 값만 지워주도록 하겠습니다.
selector = VarianceThreshold(threshold=.01)
selector.fit(train.drop(['id', 'target'], axis=1))
f = np.vectorize(lambda x : not x)
v = train.drop(['id', 'target'], axis=1).columns[f(selector.get_support())]
print('{} variables have too low variance.'.format(len(v)))
print('These variables are {}'.format(list(v)))(* 참고로 id와 target 변수는 보험금 부과 여부이므로 결과 관측에 있어 무관한 값들입니다. 빼고 훈련해줍시다!)
이후 random forest의 중요한 feature들을 기반으로 feature 선택을 하고, 여기서 선택된 피처들을 저장해줍니다.
해당 예제 코드에선 상위 50%의 변수만을 저장해주었습니다. (남길 값의 비율을 개발자가 통계적 탐구결과, 혹은 통계적 직관에 의해 자유롭게 정할 수 있습니다. 자세한 사항과 방법은 링크의 Github를 참조하세요!)
(Sebastian Raschka의 GitHub : https://github.com/rasbt/python-machine-learning-book/blob/master/code/ch04/ch04.ipynb)
완성된 Standard 스케일링을 train data에 적용해주면 끝입니다!
scaler = StandardScaler()
scaler.fit_transform(train.drop(['target'], axis=1))



