그간 따라오시느라 고생 많으셨습니다!
이제 거의 다 왔습니다.
지난 글에서는 EDA로 얻었던 insight를 기반으로 Feature Engineering을 진행했습니다.
지난 글:
[ML 대회 해설] Dacon 아파트 실거래가 예측 AI 경진대회 2등 풀이 - Feature Engineering (성공편)
지난 글에서는 EDA를 통해 각 데이터의 특성을 분석하여데이터 전처리 방법과 파생 Feature 아이디어를 얻어냈습니다. 지난 글: [ML 대회 해설] Dacon 아파트 실거래가 예측 AI 경진대회 2등 풀이 - EDA
here-lives-mummy.tistory.com
이번 글에서는 완성한 모델에 최적화된 hyperparameter와 앙상블 방법을 찾는 Tuning 과정을 보여드리겠습니다.
Hyperparameter Tuning
Model 학습 구성
이전 글에서 최종 feature engineering으로 모델을 학습시킨 결과는 다음과 같았습니다:
| Feature 수 | XGBoost | CatBoost |
| 11 | 3,482.44039 | 4,246.18452 |
저는 이 중에서 성능이 더 좋은 XGBoost를 중심으로 tuning을 진행하되,
CatBoost를 사용해 앙상블을 수행하는 방법도 염두에 두었습니다.
먼저, XGBoost를 tuning해보겠습니다.
기존에 사용한 Hyperparamter는 다음과 같습니다:
XGB_Params = {
'objective': {
'regression': 'reg:squarederror',
'binary': 'binary:logistic',
'multiclass': 'multi:softprob'
} [Task_Type],
'n_estimators': 1000,
'learning_rate': 0.3,
'tree_method': 'hist',
'importance_type': 'gain',
'random_state': 42,
}
이 중 중요한 것만 짚고 넘어가겠습니다.
n_estimator: Boosting 반복 횟수. 모델에서 생성한 트리 개수를 뜻합니다.
learning_rate: 새로운 트리가 기존 prediction값을 보정하는 정도
tree_method: 트리를 생성하는 방법. 'hist'/'exact'/'approx'/'gpu_hist' 가 있습니다. 기본 모드인 'auto' 선택 시 'hist', 'exact', 'approx' 중 나의 개발환경에 가장 적합한 것으로 자동으로 선택됩니다.
importance_type: feature 중요도를 평가하는 기준 설정 척도. 'gain', 'weight' 등이 있습니다.
각각을 하나씩 튜닝해 성능을 쥐어짜보겠습니다.
Hyperparameter Tuning은 과적합에 걸릴 가능성이 아주 높으니, 수시로 결과를 제출하여 실제 성능을 비교해보시기 바랍니다.
Tree method
Tree method는 일반적으로 (gpu) hist < approx < exact 순으로 더 좋은 성능을 냅니다.
우리는 현재 GPU를 사용하기 위해 gpu_hist를 사용 중인데요,
이를 exact로 바꾸어 성능 개선을 노려보겠습니다.
주의: XGBoost 'exact' mode는 2025년 3월 기준 GPU를 지원하지 않습니다. GPU로 실행 중이라면, CPU로 옮겨야합니다.
저는 학습하는 데에 약 2시간 정도 소모되어습니다.
Validation Score는 다음과 같습니다:
| Hist Mode | Exact Mode | |
| Validation Score | 3,482.44039 | 3,400.87654 |
시간은 많이 걸렸으나 exact mode가 압도적으로 좋은 성능을 냈네요.
n_estimator
기존 n_estimator=1000으로 조정해두고 학습을 진행했을 때의 로그입니다.
K=5로 K-Fold를 적용하였으며, 학습 시에 early-stopping-round를 적용해두어 50 round 이상 성능개선이 이루어지지 않으면 Fold가 종료되도록 하였습니다.
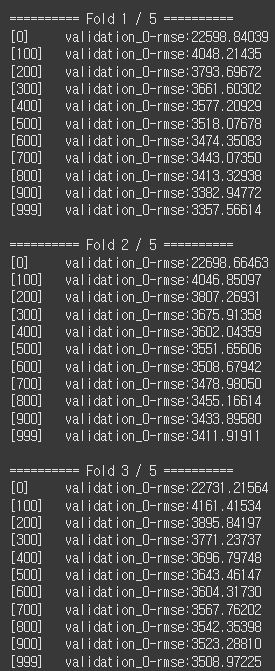

모든 Fold에서 학습이 1000번째 round까지 꽉 채워 진행된 것을 확인할 수 있습니다.
또, 모든 Fold에서 중간에 loss값의 진동 없이 학습되는 모습을 볼 수 있는데요,
이는 underfitting의 조짐으로 볼 수 있습니다.
따라서 저는 n_estimator를 5000으로 늘려주었습니다.





대부분 Fold에서 2000 ~ 2500 부근에서 early-stopping-round에 막혀 학습이 중단되었습니다.
Fold 3의 마지막 부분에서 loss가 소폭 진동하나, 미미한 수준이므로 모델이 goodfitting되었다고 볼 수 있습니다.
허나 아무리 early-stopping이 있다고 해도, 여기서는 n_estimator는 3000 쯤이 적당해보입니다.
| n_estimator=1000 | n_estimator=3000 | |
| Validation Score | 3,400.87654 | 3,302.35157 |
Learning Rate
딥러닝에서 learning rate는 일반적으로 한 번에 weight를 업데이트할 크기를 나타낸 값입니다.
learning rate가 클수록 모델 weight는 큰 스케일로 갱신됩니다.
Boosting 계열에서의 learning rate도 이와 비슷한 개념인데요,
여러 개의 모델을 순차적으로 학습하는 과정에서, 새 모델이 기존 모델의 예측을 보완할 때
얼마나 강하게 이를 반영할 지 조절하는 값입니다.
보다 정교한 학습을 위해, learning rate를 0.3에서 0.2로 줄여보겠습니다.
또한, 앞에서는 n_estimator가 3000 이전에 멈췄기 때문에 3000으로 조정하는 것이 바람직했으나
여기서는 learning rate이 줄어든 것을 감안하여 n_estimator또한 5000까지 늘리겠습니다.
early-stopping-round를 걸어두었기 때문에 과적합(overfitting)은 걱정하지 않아도 됩니다.
주의: 딥러닝에서와 마찬가지로 learning rate을 너무 작게 설정하면 학습 시간이 길어지고, 노이즈까지 학습해버리는 과적합이 발생할 수 있으니. learning rate은 적당히 조절해야합니다.
실제로 이번 대회에선 learning rate를 0.15, 0.1 ... 등으로 바꾸면 되려 모델 성능이 떨어졌습니다.





학습하는 데에 약 4-5시간 소요되었습니다.
Fold 3의 마지막 부분에서 loss가 소폭 진동하나, 미미한 수준이므로 모델이 goodfitting되었음을 예상해볼 수 있습니다.
실험 결과 Validation Score은 다음과 같습니다:
| n_estimator=3000, lr=0.3 | n_estimator=5000, lr=0.2 | |
| Validation Score | 3,302.35157 | 3,286.96496 |
n_estimator=3000에 lr=0.3으로 성큼성큼, 빠르게 학습한 것 보다
n_estimator=5000에 lr=0.2로 조금씩, 오랫동안 학습했을 때 성능이 더 좋았네요.
기타 Hyperparameter Tuning
Optuna를 활용하면 앞에서 다룬 hyperparameters 외에도
n_estimators, learning_rate, max_depth, min_child_weight, subsample, colsample_bytree, gamma, alpha, lambda, scale_pos_weight 등등...
우리가 직접 튜닝하기 어려운 여러 파라미터를 자동으로 세밀하게 조정해줍니다.
Optuna는 grid-search (a.k.a 노가다)를 사용하는 일반적인 방법과 달리, 베이지안 최적화를 사용해 최고의 경우를 찾는 방식입니다.
각 파라미터에서 시도해보고자 하는 값의 범위를 설정하고, n_trial을 넣어주면 됩니다.
study = optuna.create_study(direction='minimize', sampler=TPESampler(seed=SEED))
study.optimize(
lambda trial: objective(trial, model_name, params, X_trn, X_vld, y_trn, y_vld, esr, cat_fts),
n_trials=30
)
params.update({'n_estimators': study.best_params['n_estimators']})
params.update({'learning_rate': study.best_params['learning_rate']})
print(f"\n[Best: {study.best_trial.number}] {study.best_params}\n")여기서, n_trials는 hyperparmeter tuning을 시도해보는 횟수입니다.
저는 30번으로 설정했습니다.
주의: exact mode에서 trial을 30회로 설정하면 2시간 * 30회 = 약 60시간을 기다려야 한다는 점 감안하시기 바랍니다.
또한 Optuna를 사용한 tuning에서는 과적합의 위험이 있으니 언제나 결과를 제출하여 public score을 확인해보셔야합니다.
저는 Optuna로 hyperparameter tuning을 여러번 시도해봤으나 특별히 좋은 수확은 없었습니다.
Data Weight Sampling
Boosting 계열 모델에서는 각 데이터의 중요도를 조정하여 학습시키는 옵션이 있습니다.
데이터에 sample_weight라는 feature를 만들어 붙인 뒤, 그 feature를 sample_weight 인자로 넘기면 반영됩니다.
보통 다음과 같은 상황에서 고려되는 방법입니다:
- 중요한 데이터를 더욱 강조해서 학습시키고 싶을 때
- 데이터의 분포가 불균형하나, 여건상 oversampling을 할 수 없을 때
우리는 trainset은 2009년부터 2017년의 거래데이터를 갖고 2017년 거래데이터로만 구성된 testset을 예측하는 시계열 task를 수행하고 있습니다.
그럼 2009년 데이터와 2017년 데이터 중 어느 것이 2017년 거래를 예측하는 데 더 도움이 될까요?
그렇습니다, 아마 2017년 데이터 일 것입니다.
2017년도 데이터는 시간이 지남에 따라 부동산 정책 변화, 물가상승, 건물 노화 등 다양한 요인으로 인해 2009년 데이터와 많이 다를 수 있습니다.
이는 거래년도에 따른 Target값의 분포만 그래프로 그려봐도 바로 알 수 있습니다.

시간이 지남에 따라 평균 거래가격이 급상승하는 양상을 보입니다.
이는 즉슨 2009년 데이터를 기반으로 모델이 백날 거래가를 예측해봤자 2017년 데이터에 부합하지 않을 가능성이 높다는 뜻입니다.
따라서 저는 거래년도를 기준으로 데이터에 weight를 부여해보았습니다.
2017년에 가까울수록 높은 sample weight를, 2009년에 가까울수록 낮은 sample weight를 부여해보겠습니다:
for df in [train, test]:
df['transaction_year'] = df.transaction_year_month // 100
weight_mapping = {2008:0.05, 2009:0.06, 2010:0.07, 2011:0.08, 2012:0.09, 2013:0.1, 2014:0.11, 2015:0.13, 2016:0.15, 2017:0.16}
for df in [train, test]:
df['sample_weight'] = df['transaction_year'].map(weight_mapping)
# train loop 중략...
# 모델에 적용시키려면 sample_weight인자에 해당 column만 넘겨주면 됩니다.
model.fit(X_trn, y_trn, eval_set=eval_set, verbose=verbose, sample_weight=train['sample_weight'])* 주의: weight의 합은 꼭 1이 되지 않아도 됩니다. 1, 3, 100 등등 자유롭게 조절해주셔도 무관합니다.
하지만 이 접근은 실제로 적용시켜보면 오히려 성능을 떨어뜨리는 것을 볼 수 있습니다.
이는 아마 transaction_year_month로 표상되는 시간 feature가 실제 모델에서 큰 역할을 못했음에도 불구하고
이를 기준으로 weight sampling을 진행하는 바람에 모델이 2017년 데이터에 과도하게 집중하게 되며,
전체적인 데이터 패턴을 제대로 학습하지 못해 생긴 문제로 보입니다.

결론
정리하면, 제가 시도해본 Model Tuning은 다음과 같습니다:
1. Tree method 바꾸기
2. n_estimator 늘리기 (early-stopping round 추가 필수)
3. Learning rate 줄이기
4. Optuna를 사용한 hyperparameter tuning
5. 거래년월 기준으로, 2017에 가까울수록 높고 2009에 가까울수록 낮은 Sample weight 적용시키기
이 중에서, 실제 효과를 보인 것은
1. Tree method 바꾸기
2. n_estimator 늘리기 (early-stopping round 추가 필수)
3. Learning rate 줄이기
이 세 가지였습니다.
비록 저는 4번 방법에서 그렇다할 성과를 얻지 못했지만,
컴퓨터 자원이 충분하신 분이라면 저보다 많은 hyperparameter 조합을 시도해 좋은 결과를 얻을 수도 있을 거예요.
이로써 대회 본 풀이를 마무리하겠습니다.
여기까지 오느라 고생 많으셨습니다!
다음 글에서는 시도해보았으나 좋은 결과를 내지 못했던 다양한 Feature Engineering 방법을 소개하겠습니다.
도움이 되었다면 하트를 눌러주세요 :)
구독하시면 더 많은 데이터사이언스 정보와 대회풀이를 보실 수 있습니다!




